My understanding of pattern matching and string manipulation in lua is limited at best. I'm currently developing a library that will use a tree structured dictionary to look up possible suggestions as the user inputs text into an EditBox.
The dictionary will be split into two parts; one static, default dictionary with pre-defined entries and one dynamic dictionary which uses the current text of the EditBox to further add suggestions.
My question is regarding how I can strip a lengthy piece of text of all characters that are not words in the best way. My current approach is using a table of "forbidden" characters which is then used to replace each occurrence with whitespace. After that, all multiple occurences of whitespace are replaced by single whitespaces before splitting the string into table entries. This results in a lot of repeats in the returned substrings because syntax is rarely used just once. Can this be done more efficiently?
This is what the code looks like:
Lua Code:
-- Byte table with forbidden characters
local splitByte = {
[1] = true, -- no idea
[10] = true, -- newline
[32] = true, -- space
[34] = true, -- ""
[35] = true, -- #
[37] = true, -- %
[39] = true, -- '
[40] = true, -- (
[41] = true, -- )
[42] = true, -- *
[43] = true, -- +
[44] = true, -- ,
[45] = true, -- -
[46] = true, -- .
[47] = true, -- /
[48] = true, -- 0
[49] = true, -- 1
[50] = true, -- 2
[51] = true, -- 3
[52] = true, -- 4
[53] = true, -- 5
[54] = true, -- 6
[55] = true, -- 7
[56] = true, -- 8
[57] = true, -- 9
[58] = true, -- :
[59] = true, -- ;
[60] = true, -- <
[62] = true, -- >
[61] = true, -- =
[91] = true, -- [
[93] = true, -- ]
[94] = true, -- ^
[123] = true, -- {
[124] = true, -- |
[125] = true, -- }
[126] = true, -- ~
}
local n = CodeMonkeyNotepad -- the editbox
local text = n:GetText() -- get the full text string
local space = strchar(32)
-- Replace with space
for k, v in pairsByKeys(splitByte) do
-- treat numbers differently
if k < 48 or k > 57 then
text = text:gsub("%"..strchar(k), space)
else
text = text:gsub(strchar(k), space)
end
end
-- Remove multiple spaces
for i=10, 2, -1 do
text = text:gsub(strrep(space, i), space)
end
-- Collect words in table
local words = {}
for k, v in pairsByKeys({strsplit(space, text)}) do
-- ignore single letters
if v:len() > 1 then
words[v] = true
end
end
Here's an example output, using the actual code as text inside the EditBox:
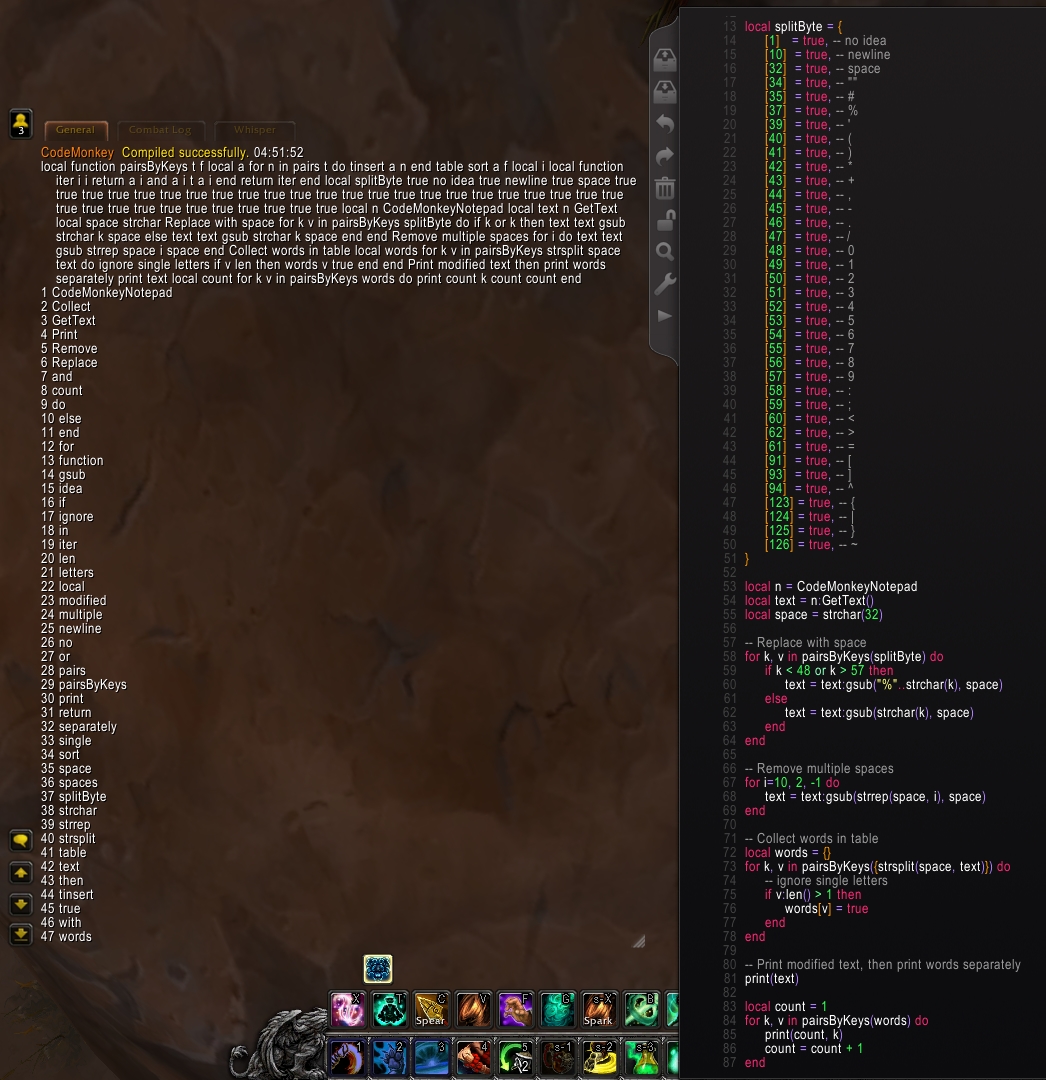
Note: pairsByKeys is just a custom table iterator that sorts by key.